Many of us can relate to a story of a health scare like this, either through a personal experience or that of a loved one. And if the human body is a metaphor for society, with all its beauty and its ailments, would we not want to dig beneath the surface of our collective symptoms - reflected in our data - to move towards a healthier shared future?
Social data – in numbers, in words - are meant to reflect the functioning of society. But what lies underneath the data? Who is represented in the data, and who is not? What are the social processes and interactions that generate such data?
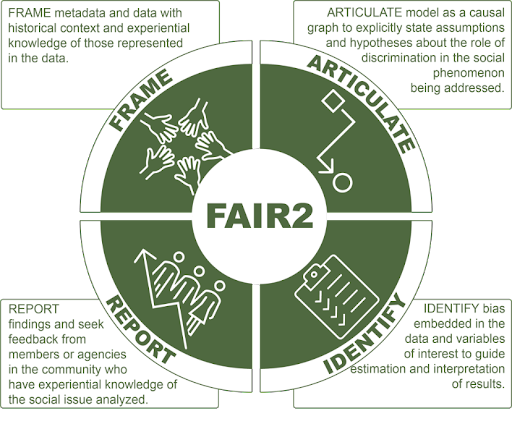
We have taken big steps in capturing fine grain data from the human experience. We have developed data tools to process, link, visualize, predict, and draw inference from data. But the interpretations, predictions and inferences we make depend not only on the data themselves, but on the social processes that generate data, and the assumptions with which we contextualize the data.
If data science is to serve the public good, we must continually ask difficult questions about data, data provenance, and metadata, questions like:
Who is carrying the burden of disease but does not appear with a diagnosis in health records, and why?
How are people classified into categories of racial, ethnic and gender categories, and why?
Who is more likely to appear in administrative records documenting encounters with police, and why?
History provides a cautionary tale for those of us who seek to use data to advance social welfare. The history of social sciences and social data is plagued by misuse, abuse, and flawed logic: “[This] is not an easy book. Nor should it be”, writes Khalil Gibran Muhammad in The Condemnation of Blackness, a history of racism in early social sciences and crime statistics. We learn of how census and prison data fields were conceived in the early 1900s to organize people into more and less deserving groups, and how prominent social scientists and statisticians paired these data with flawed logic and assumptions to make causal claims portraying Black people as criminals.
We also learn of the courageous response of Black scholars and activists like mathematician Kelly Miller, sociologist W. E. B. DuBois, and journalist Ida B. Wells, whose carefully crafted counterarguments hinged on data, logic, and experiential knowledge.
“For good or for bad, the numbers do not speak for themselves,” Dr. Muhammad writes in his conclusion. “The invisible layers of racial ideology packed into the statistics, sociological theories, and the everyday stories we continue to tell about crime in modern urban America are a legacy of the past. The choice about which narratives we attach to the data in the future, however, is ours to make.”
It was not until 2020, during widespread protests against institutional racism, that academic associations acknowledged the role of data technologies in creating and sustaining systems of racial oppression. The threat of misusing data technologies to perpetuate or even strengthen discrimination is real – as is the potential they offer to advance social justice.